Используем Python для автоматизации SEO процессов и отслеживания конкурентов с помощью Питона и Data Studio.

О чем поговорим?
Независимо от того, являетесь ли вы новичком в SEO или опытным специалистом, изучение падения позиций ключевых слов — это только одна часть профессии.
Существует множество способов определения причины, почему ваши целевые ключевики могут потерять свои позиции, но использование Python и Data Studio в корне меняет положение дел!
Быстрое заявление об отказе: я не создавал этот скрипт. Я сотрудничал с SEO специалистом и разработчиком, Эваном из компании «Architek», чтобы решить конкретную проблему, которая у меня была. Эван был мозгом при создании скрипта.
Я всегда хотел иметь возможность просматривать большое количество результатов Google, без необходимости поиска каждого вручную. Эван упомянул, что Python может быть идеальным решением для решения задач в области SEO-анализа.
Почему Python представляет интерес для SEO?
Python — невероятно высокопроизводительный язык программирования, который может делать практически все. Одним из наиболее распространенных применений для Python является автоматизация ежедневных монотонных задач.
Одна из самых крутых вещей в Python — это несколько разных способов выполнения одной и той же задачи. Однако это делает его немного сложнее. Большинство примеров скриптов Python могут быть немного устаревшими, поэтому вы будете изучать все методом проб и ошибок.
На базе Python есть много приложений для анализа SEO данных. Ключ должен иметь правильный смысл. Если вы намереваетесь автоматизировать задачу, есть вероятность, что для нее можно создать скрипт.
Чтобы быть в курсе последних вариантов использования Python в SEO, Гамлет Батиста опубликовал несколько замечательных статей здесь, в Search Engine Journal.
Что делает и не делает этот конкретный скрипт
Большинство инструментов ранжирования по ключевым словам предоставляют средний рейтинг по ключевому слову за указанный период времени.
Этот скрипт Python выполняет одну индексацию во время запуска с вашего IP-адреса. Этот скрипт не предназначен для отслеживания рейтинга ключевых слов.
Цель этого скрипта состояла в том, чтобы решить проблему, с которой я столкнулся при исследовании падения позиций моего клиента и его конкурентов.
Большинство инструментов ранжирования по ключевым словам могут показать вам рейтинг страниц вашего домена, но не рейтинг страниц ваших конкурентов по ключевому слову.
Так почему это важно?
В этом случае мы не влияем на эффективность страницы на долгое время. Мы просто пытаемся получить оперативные данные.
Этот скрипт позволяет нам быстро выявлять тенденции в органике и видеть, какие страницы работают лучше всего.
Что нужно для начала работы?
Если вы новичок в Python, я рекомендую ознакомиться с официальным руководством по Python или автоматизацией скучных вещей.
Для этого учебного руководства я использую PyCharm CE, но вы можете использовать Sublime Text или любую другую среду разработки.
Этот скрипт написан на Python 3 и может быть немного сложным для новичков в этом языке программирования.
Если вы еще не нашли интегрированную среду разработки или не настроили свое первое виртуальное окружение, это руководство поможет вам начать.
После настройки нового виртуального окружения вам потребуются следующие библиотеки:
- urllib
- lxml
- requests
Теперь, когда все настроено, давайте вместе углубимся в изучение.
1. Составьте список ключевых слов для исследования
Мы будем использовать образцы данных, чтобы исследовать некоторые ключевые слова, которые мы собираемся отслеживать.
Давайте представим, что вы посмотрели на свое программное обеспечение для отслеживания ключевых слов и заметили, что следующие ключевые слова опустились более чем на пять позиций:
- Полезные советы по SEO
- Локальная SEO консультация
- Изучение SEO
- Статьи по поисковому продвижению
- SEO блог
- Основы SEO
Первое, что мы сделаем, это поместим эти ключевые слова в простой текстовый файл searches.txt. Ключевые слова должны быть разделены переносом строки, как показано на скриншоте ниже.
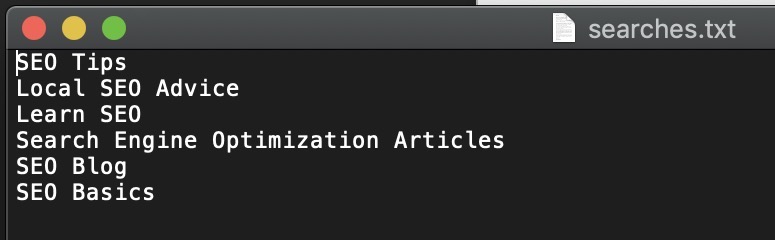
2. Запуск скрипта исследования позиции Python
Вкратце, этот скрипт выполняет три основных функции:
- Находит и открывает ваш файл searches.txt.
- Использует эти ключевые слова и ищет первую страницу Google для каждого результата.
- Создает новый CSV файл и печатает результаты (ключевое слово, URL-адрес и заголовки страниц).
Чтобы скрипт работал правильно, вам нужно будет запустить его по разделам. Во-первых, нам нужно будет сделать запрос к нашим библиотекам. Скопируйте и вставьте код ниже.
from urllib.parse import urlencode, urlparse, parse_qs
from lxml.html import fromstring
from requests import get
import csvДалее вы сможете ввести основную функцию scrape_run() этого скрипта одним действием копирования/вставки.
Эта часть скрипта устанавливает фактически предпринятые шаги, но не выполнит команду до третьего шага.
def scrape_run():
with open('searches.txt') as searches:
for search in searches:
userQuery = search
raw = get("https://www.google.com/search?q=" + userQuery).text
page = fromstring(raw)
links = page.cssselect('.r a')
csvfile = 'data.csv'
for row in links:
raw_url = row.get('href')
title = row.text_content()
if raw_url.startswith("/url?"):
url = parse_qs(urlparse(raw_url).query)['q']
csvRow = [userQuery, url[0], title]
with open(csvfile, 'a') as data:
writer = csv.writer(data)
writer.writerow(csvRow)Теперь вы можете запустить команду. Последний шаг — скопировать/вставить команду ниже и нажать клавишу ввода.
scrape_run()
Готово!
3. Используйте Data Studio для анализа результатов
Запустив эту команду, вы можете заметить, что был создан новый CSV-файл с именем data.csv. Это ваши необработанные результаты, которые нам понадобятся на последнем этапе.
Мое агентство создало удобный шаблон Data Studio для анализа ваших результатов. Чтобы использовать этот бесплатный отчет, вам нужно вставить свои результаты в Google Sheets.
На странице, приведенной выше по ссылке, есть подробные инструкции по настройке отчета Data Studio.
Как проанализировать наши результаты?
Теперь, когда у вас готов новый отчет Data Studio, пришло время разобраться во всех этих данных.
То, что мы ищем, это шаблоны. Да, вы можете найти шаблоны в необработанных данных, но этот шаблон Data Studio имеет удобную функцию, которая позволяет нам быстро определить, какие страницы наиболее часто ранжируются по целевым ключевым словам.
Это полезно, поскольку позволяет нам видеть, какие конкуренты работают хорошо, а также какие конкретные страницы работают хорошо.
Как вы можете видеть на скриншоте Data Studio выше, Moz и Ahrefs являются двумя конкурентами, ранжирующими наши ключевые слова.
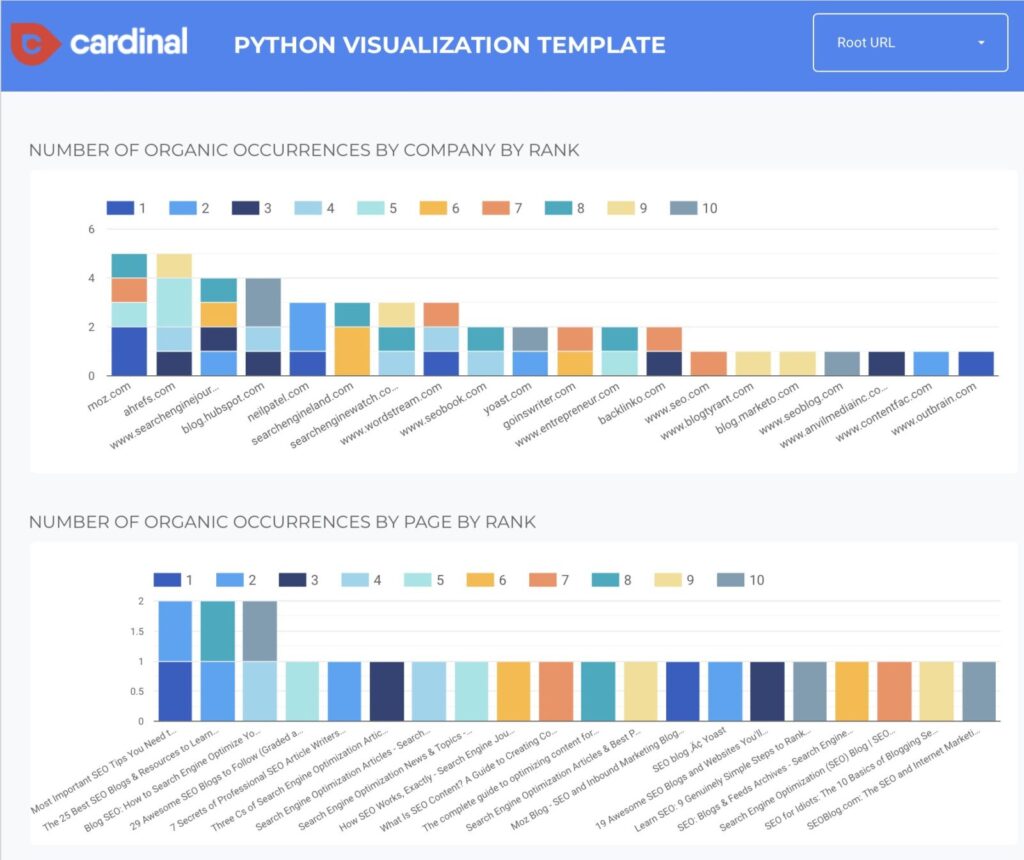
Однако это не помогает нам точно определить, что они делают для ранжирования по этим ключевым словам.
Вот где пригодится вторая блок-схема. Она отображает ранжирование каждой страницы и сколько раз они встречаются по всем нашим поисковым запросам. Мы быстро можем определить три наиболее эффективные страницы по нашим ключевым словам.
Нужно отфильтровать до определенного уровня страницы или ключевого слова?
Мы включили фильтры в верхней части шаблона Data Studio, чтобы упростить этот процесс.

После того, как вы составили список самых эффективных страниц, вы можете провести дальнейший анализ страницы и других страниц, чтобы выяснить, почему эти страницы работают так хорошо.
Застряли?
Если вы застряли, обратитесь к изобретателю этого скрипта для получения советов или индивидуального решения для программирования. А что думаете вы?
Надеемся, что эта статья способствовала возникновению творческих идей о том, как вы можете использовать Python для автоматизации ваших SEO процессов.